The theory of grammar and how sentences are formed
The theory of grammar
In the first lecture, we discussed what linguists mean when they use the term grammar and how this differs from more popular usage. Specifically, while many others are concerned with prescriptive grammar, which sets down guidelines for how people should speak or write, we are concerned with descriptive grammar, which attempts to describe how people actually speak and to determine the system of knowledge that underlies this.
Now, a descriptive grammar, even if it is very detailed, is frequently rather simple. It is often little more than a list of certain properties of the language in question. For example a descriptive grammar of English might tell us things like the subject usually comes before the verb and the object usually comes after, or that most verbs have an -s ending in the present tense when their subject is 3rd person singular:
John eats scrapple. Loretta walks to school.
This is all well and good, and in fact descriptive grammars of unfamiliar languages are absolutely indispensable for serious linguistic work. However, we would like to go still deeper, for example to explain why the object sometimes comes before the verb or the subject sometimes come after the verb in English:
That guy I don't like .
Down goes Frazier! (Howard Cosell's call of George Foreman knocking out Joe Frazier in 1973)
What is a theory of grammar?
Theoretical linguistics is dedicated to answering questions of this sort. Here we use the term grammar in a more specific sense. A grammar is the complete system that underlies a language, not just a few facts about it, but a full apparatus that expresses the relationships between those facts. Thus we call the (subconscious) knowledge that a speaker has of their own language a grammar, and we call our theories of what that knowledge might be like grammars. Our goal ultimately is to get out theory of grammar to approximate the grammar in the speaker's mind. That is, we want a theory that does the same things the linguistic ability of a person who speaks a given language, which can produce all the sentences the human speaker can produce, and interpret all the sentences the human speaker can interpret.
An analogy for the difference between a basic descriptive grammar and a theory of grammar can be drawn from descriptions of a car engine. On the one hand, you have the list of the engine's specs that the car dealer shows to his customers, listing things like how many cylinders the engine has, how large it is and how many horsepower it puts out. This is like a descriptive grammar, because it tells you a lot of facts about the engine but doesn't really tell you how it works. Consider the following specs for Ford Mustangs taken from the Ford website:
| Performance Specs |
| Powertrain | |||||
| Coupe | GT Coupe | Convertible | GT Convertible | Mach I | |
| Engine | Split Port Intake 3.8L OHV SEFI V-6 | Split Port Intake 4.6L SOHC SEFI V-8 | Split Port Intake 3.8L OHV SEFI V-6 | Split Port Intake 4.6L SOHC SEFI V-8 | MOD 4.6L DOHC V-8 |
| Displacement | 232 CID | 281 CID | 232 CID | 281 CID | 281 CID |
| Horsepower (SAE net @ rpm) | 193 @ 5500 | 260 @ 5250 | 193 @ 5500 | 260 @ 5250 | 305 @ 5800 |
| Torque (lb.-ft. @ rpm) | 225 @ 2800 | 302 @ 4000 | 225 @ 2800 | 302 @ 4000 | 320 @ 4200 |
| Compression Ratio | 9.3:1 | 9.4:1 | 9.3:1 | 9.4:1 | 10.1:1 |
| Bore and Stroke (in.) | 3.80 x 3.40 | 3.6 x 3.6 | 3.80 x 3.40 | 3.6 x 3.6 | 3.6 x 3.6 |
| Fuel Delivery | Multi-Port Fuel Injection | Multi-Port Fuel Injection | Multi-Port Fuel Injection | Multi-Port Fuel Injection | Multi-Port Fuel Injection |
On the other hand, you have the schematic diagrams of the engine used by auto mechanics to do repairs, which show how it is put together out of a series of smaller parts and depicts how everything fits together to accomplish the complicated task of actually getting the car to move. This is roughly what a good theoretical grammar should be like. Consider the following schematic diagram of a portion of the engine from an older model Mustang from an enthusiasts' website:
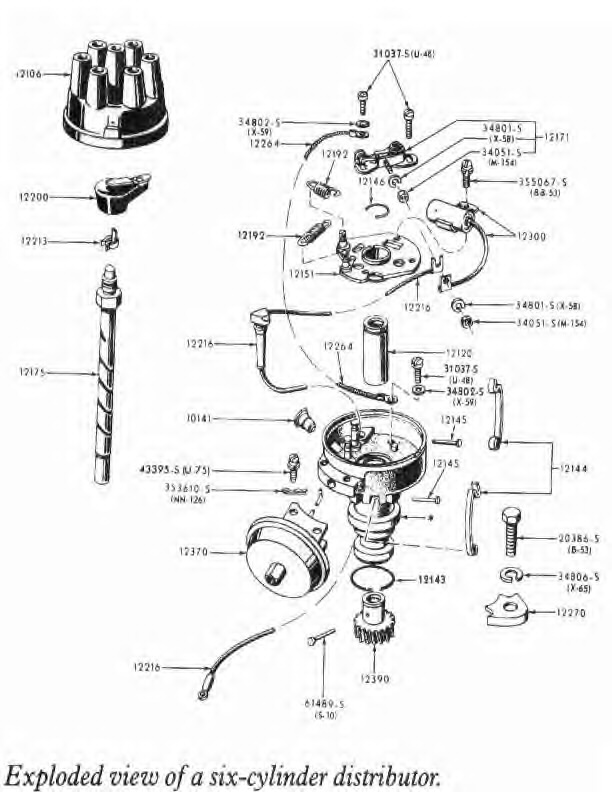
In the lectures 2 and 3 we looked at some fragments of a theory of English grammar dealing with the sound structure and word structure of language. For instance, phonological rules for flapping and raising, and the interaction of these rules is the kind of description that tells us how the language-sound is put together out of a series of smaller parts.
The development of formal theories of grammar
So now that we have some idea of what a theory of grammar is, we can take a quick look at the history of specific theories.
Over the centuries, there have been many efforts to provide a rigorous, formal account of the grammar of natural language with various motivations, the most important being:
- to provide a basis for teaching grammar and rhetoric
- to put philosophical and mathematical discourse on a solid foundation
- to increase scientific understanding of human languistic abilities
- to provide a basis for computer processing of natural languages
Ancient beginnings
One early example is the grammatical tradition of ancient India, with its most famous figure, Panini (ca. 520 BCE - ca. 460 BCE). The Indian Grammarians were concerned with preserving Sanskrit, the sacred language of Hinduism, in its Classical form, in order to ensure that it would be used properly in ritual. To do this they described every facet of the language in minute detail, with a precision unrivaled elsewhere until the 20th century. Their crowning achievement was Panini's Grammar, a mammoth work detailing the step-by-step derivation of Sanskrit sentences, all the more impressive because it was not written down, but memorized in verse. For those who might be curious, one of the world's foremost scholars of Indian grammatical theory and Panini in particular, George Cardona, is on the linguistics department faculty here at Penn.
The grammatical traditions of ancient Greece and Rome are responsible for a great deal of the terminology that has passed into modern grammatical theory, and they had a number of important insights, passed down to us through the medieval grammarians but they were ignorant of the work of the Indian grammarians, and their descriptions and theories never reached as high a level of sophistication and detail.
Lively and productive grammatical traditions existed also in China, the Arab world, and various other cultures as well, but they have played less of a role in shaping modern grammatical theory (for mostly historical and cultural rather than purely linguistic reasons).
The beginnings of modern linguistics can be traced to the mid-19th century when Europeans came to India in large numbers and began to learn Sanskrit and become familiar with the ancient Indian grammatical tradition. The main early thrust of linguistic work was born out of the realization that Sanskrit was historically connected to the well-known languages of Europe. This area of study, called Historical Linguistics, was dedicated to comparing languages, determining the historical relationships which obtain between them, and attempting to figure out what older stages of the languages in question must have looked like. We will discuss this in a future lecture.
But the marriage of older European and Indian grammatical traditions and the detailed descriptive work necessary to do good language comparison also led to a new level of sophistication in linguistic description and grammatical theory.
Still, the grammars of the late 19th and early 20th century were not what we would call full-blown theoretical grammars. As with previous traditions, the work took place in the tradition of the humanities, rather than that of mathematics or the natural sciences. Consider the following quote from Otto Jespersen:
- The definitions [of the parts of speech] are
very far from having attained the degree of exactitude found in
Euclidean geometry. [Philosophy of Grammar, 1924]
In earlier centuries, this would have been a sort of scholarly joke, like complaining about the lack of axiomatic foundations for the game of golf. In the philosophical context of the 20th century, it has been felt as a serious criticism. The logical positivists made Hume's "principle of verification" an article of faith:
- When we run over libraries, persuaded of these
principles, what havoc must we make? If we take in our hand any volume;
of divinity or school metaphysics, for instance; let us ask, Does it
contain any abstract reasoning concerning quantity or number? No. Does
it contain any experimental reasoning concerning matters of fact and
existence? No. Commit it then to the flames: for it can contain nothing
but sophistry and illusion.
[Enquiry Concerning Human Understanding]
Although radical positivism made few converts, and was thoroughly discredited as a philosophy of science, it expresses a skeptical and empiricist perspective that pervades 20th-century intellectual life. The defining feature of the development of linguistics since the early 20th century has been the increased influence from, and desire to imitate, mathematics and the natural sciences.
The logical grammarians
One approach taken to addressing this concern was born essentially from the study of logic and mathematics, and is associated with names like Gottlob Frege and Bertrand Russell, Alfred Tarski and Richard Montague. The basic enterprise of these researchers has been two-fold:- to devise more expressive or more interesting kinds of formal logic
- to show how natural languages can be interpreted by reference to such logics
One of the most famous works in this tradition is Montague's article English as a formal language, in which he provides a recursive truth definition for a fragment of English exactly as if it were a formal language (like predicate logic).
The strength of this tradition has been its careful attention to giving an account of meaning, especially in such troublesome areas as quantifiers ("some", "every", "few"), pronouns, and their interactions. It is not easy to provide a recursive truth definition for sentences like "Every farmer who owns a donkey beats it," or "someone even cleaned the BATHROOM," but in fact the semantic properties of such sentences can be predicted by contemporary theories in this area.
Work in this tradition has been less influential in areas outside of semantics, but has had some impact on syntax, which we'll be discussing below.
Zellig Harris and Operationalism
One of the ideas underlying the natural science-influenced perspective as it has made itself felt in linguistics is the principle of operationalism, which requires that any concept involved in "experimental reasoning concerning matters of fact and existence" must be defined in terms of clearly defined operations, to be performed in any given situation in order to decide whether an instance of that concept has been observed.
That is, rather than defining terms like "noun", "verb" or "subject" in vague impressionistic terms like "a noun is a person, place or thing", an operational definition must be precise, exact, deterministic and without exceptions, and must be in terms of how the given entity is related to processes of the system.
In this context, Zellig Harris (a key figure in American structuralist linguistics, Noam Chomsky's teacher, and the founder of the linguistics department at Penn) undertook to provide operational definitions of core linguistic concepts such as "phoneme," "morpheme," "noun," "verb" and so forth (we'll come back to what these various terms mean later on).
He took the basis for his definitions to be observations of utterances, that is, he took a mass of sentences that people had actually written or said, and tried to define things like "noun" based on how they appeared in that mass of data.
He used concepts from the then-new discipline of information theory to suggest procedures that could be used to define a hierarchy of segmentation and classification inductively.
In those days before adequate computers were accessible (the late 1940's and early 1950's), Harris' techniques were conceptual ones, based on the conviction that the essence of language could be found in the distributional properties of its elements on all levels. Since then, people have tried implementing some of his inductive methods, and have found that they work, to a degree.
Noam Chomsky and generative grammar
This brings us to the hands down most important figure in modern grammatical theory, Noam Chomsky.
As mentioned above, Chomsky was Harris' student, and he took up the task of providing operational definitions for the concepts of syntax (sentence structure) -- noun, verb, sentence and the like. He found the problem to be much more difficult than had been previously realized. As he worked on it, two things happened.
First, he realized that he was working on the problem of language learning. A procedure for figuring out grammatical concepts from a set of utterances can be seen as a way to study the distributional properties of the pieces of language (that is, where certain words or other elements show up, and where they don't), or as a way to make linguistics respectable by positivist standards -- but it can also be seen as an idealized or abstracted version of what a child accomplishes in learning his or her native language. That is, when a child learns her language, she has to figure out what types of words there are and what the rules are for combining them into sentences.
A typical child also completes this task more rapidly than Chomsky, as an adult, completed his investigation. In fact, 50+ years later, Chomsky and company are still working on the problem. This led Chomsky to conclude that the child has an unfair advantage: being born with key aspects of the answer already given in the make up of her brain.
Chomsky's second innovation was to dig deeper into the basic mathematics of syntax, along with collaborators like the French mathematician Marcel-Paul Schuetzenberger. We won't go into the details of this here, but what is important is that Chomsky adopted a very specific definition of a language. For him, it was just a typically infinite set of strings of symbols.
For example, a in a human language the strings are sentences made out of a set of symbols which are words. In this sense, English is all of the grammatical setences you could possibly create out of the set of English words.
This is a long way from what the word language means in everyday life, just as the mathematical concept of line is quite far away from an actual line drawn in the sand or on a chalkboard. In the discussion below, we'll put the word "language" in scare quotes when we mean it in this abstract mathematical sense.
Contrary to the practice of the logical grammarians, this perspective ignores the question of meaning, and focuses exclusively on form. A "language," in this mathematical sense, has no meaning at all -- unless we provide one by some additional means.
Chomsky investigated the properties of formal systems for defining or "generating" such sets, and of abstract automata (machines) capable of determining whether a given string is a member of a particular set or not. This had important consequences for certain types of mathematics and especially computer science which will not concern us here directly.
What is important for linguistics is that this allowed a new and, for positivists, very attractive way to think about theoretical grammar.
This is what is known as "generative grammar", Chomsky's idea that our theory of grammar should in fact be a formal mechanism that can "generate" all of the possible sentences of a given language, and nothing else. So a generative grammar of English should be a set of rules or processes or whatever that can produce sentences like John likes pizza but not John pizza likes
Modularity
Any number of generative theories of grammar have been proposed over the past several decades, and we will not go into the details and differences, but will instead focus on some of the major mainstream ideas, which turn out to correspond more or less to Chomsky's own constantly developing theory.
The only overall point that I wish to make here before we start talking about some specifics is that all generative theories of grammar are modular. That is, they divide up the work of putting together a sentence into a several parts, each taken care of by a module which is linked in some way to the other modules.
This is idea is actually not restricted to generative linguistics, having its roots in the tradional distinctions between syntax, morphology, phonology and so forth. However, it has reached new importance in generativism, being looked at not as a convenient way to describe languages, but as a design feature of language itself.
This means that it now becomes more important to justify how one divides the modules and also forces one to be explicit about how they connect to one another. Indeed, this is one of the main points along which different modern grammatical theories differ, and we will get to discuss some of the issues and controversies.
Still, there is generally at least rough agreement on what the main modules are, and in the next several lectures we will go through them one by one, talking about the relevant issues and looking at a few real problems that researchers are working on.
These modules are, by the way, the "Subfields concerned with some part of the linguistic system" that we talked about in Lecture 1. Here's short list, in the order we'll deal with them:
- Syntax: the structure of sentences
- Morphology: the structure of words
- Phonetics: the production and perception of linguistic sounds
- Phonology: the sound patterns of language
- Semantics: the meanings of words and sentences
- Pragmatics: context and language use
Syntax: the structure of sentences
The modules of language we talked about first are phonology and morphology, and today we're moving to the larger units of linguistic structure today to discuss syntax, the part of the linguistic system that is responsible for constructing sentences out of smaller elements like words.
Background: why syntax?
A crucial fact about language is that it is not just a jumble of words thrown together, but involves rigid structures and rules of combination. It is entirely reasonable to ask why this should be.
We can communicate a lot without words, by the expressive use of eyes, face, hands, posture. We can draw pictures and diagrams, we can imitate sounds and shapes, and we can reason pretty acutely about what somebody probably meant by something they did (or didn't do).
Despite this, we spend a lot of time talking. Much of the reason for this love of palaver is no doubt the advantage of sharing words; using the right word often short-cuts a lot of gesticulating and guessing, and keeps life from being more like the game of charades than it is.
Given words, it's natural enough to want to put them together. Multiple ``keywords'' in a library catalog listing can tell us more about the contents of a book than a single keyword could. We can see this effect by calculating the words whose frequency in a particular book is greatest, relative to their frequency in lots of books. Here are a few sample computer-calculated lists of the top-10 locally-frequent words, for each of a range of books on various topics (taken from the Pinker book):
"College: the Undergraduate Experience:" undergraduate faculty campus student college academic curriculum freshman classroom professor.
"Earth and other Ethics:" moral considerateness bison whale governance utilitarianism ethic entity preference utilitarian.
"When Your Parents Grow Old:" diabetes elderly appendix geriatric directory hospice arthritis parent dental rehabilitation
"Madhur Jaffrey's Cookbook:" peel teaspoon tablespoon fry finely salt pepper cumin freshly ginger
In understanding such lists, we are making a kind of semantic stew in which the meanings of all the words are stirred up together in a mental cauldron. We get a clear impression of what the book is about, but there is a certain lack of structure.
For example, the last word list gives us a pretty good clue that we are dealing with a cookbook, and maybe even what kind of cuisine is at issue, but it doesn't tell us how to make any particular dish.
Just adding more words doesn't help: the next ten in order from the (Indian) cookbook are:
- stir lemon chicken juice sesame garlic broth
slice sauce chili
This gives us some more information about ingredients and kitchen techniques, but it doesn't tell us how to make a vindaloo. To understand a recipe, we need more exact information about how the words (and ingredients!) combine. This is why we need syntax.
But how much help do we really need from syntax?
Let's suppose that we know what words mean, and a lot about how to put meanings together, but we have few constraints on syntactic structure. For example, there will be a rule making sure that semantically-related words will be closer together than semantically-unrelated words are, but little else. After all, all we're really interested in is getting across some information.
Under these circumstances, we could probably understand a lot of everyday language, because some ways of putting words together make more sense than others do. So we can be pretty sure of who did what to whom given the following:
Francine, pizza, eat
We know that there's some sort of eating going on, and since food items like pizza don't eat, but typically are eaten, we can figure out that it is Francine who does the eating and the pizza that gets eaten.
But often more than one interpretation is plausible.
Pat, Chris, glass, break, saw.
"Pat saw Chris break the glass."
"Chris saw Pat break the glass."
Without principles for the combination of these words (or the interpretation of their combination), it's impossible to distinguish these meanings.
We are in something like this condition when we try to read a word-for-word gloss of a passage in a language we don't know. Often such glosses can be understood: thus consider the following sentence in Kashaya, an American Indian language of northern California.
| tíiqa | mito | taqhma | c'ishkan | shaqac'qash | |
| I wish | you | dress | pretty | might wear |
"I wish you might wear a pretty dress"
In this case the meaning of the parts makes it reasonable to figure out the whole. But in other cases, the interrelations are less obvious based on their individual meanings, and knowledge of the syntax is essential.
| muukín' | tito | 'ama dút'a' | dihqa'khe' | dúucic'iphi t'o | daqaac'i'ba | |
| he | him | job | will give | if know | would like |
A speaker of English might be inclined to interpret this as:
"He will give him a job if he knows that he'd like it."
That makes sense based on English syntax: notice that the order of the verbs is the same in the translation.
But in fact it means:
"He would like it if he knew someone was going to give him a job"
because in Kashaya, the main verb occurs at the right, and the more subordinate verbs precede that final main verb. The only way to be sure about this is to know Kashaya syntax.
This is what syntax does. It provides a set of procedures and rules that we can use to put words together in consistent ways to represent ideas in predictable ways, particularly the relationships between words that might not be obvious from their meanings.
Because both the speaker and the hearer have access to the same rules, the former can assume that when he follows the rules, the latter will understand what he means.
An interesting point about syntax, and language in general, is that the rules themselves are largely arbitrary, thus they can vary from language to language. For example, it really doesn't matter whether a language puts a verb in front of its arguments or behind them, as long as it always does the same thing, and indeed as we've seen, English and Kashaya differ on this point.
Of course, we don't actually have to look beyond English for evidence that syntax is independent of semantics (the meaning of the sentence and its elements). For one thing, it is entirely possible to make up sentences that faithfully follow the rules of English syntax, yet are complete nonsense, like the following famous example:
Colorless green ideas sleep furiously.
Similarly, we can construct examples that violate some rule of English syntax and thus clearly sound wrong to English speakers, yet are easily interpreted:
This child seems sleeping.
Harris dined the steak.
Neurological agrammatism
An interesting demonstration of the role played by syntax comes from instances where it does not function properly.
This is the case with people whose ability to process syntactic structure is neurologically impaired, even though other aspects of their mental functioning, including their understanding of complex propositions, may be intact.
In the last lecture we talked about a disorder called Wernicke's aphasia, which involved difficulty with remembering and using content words like nouns and adjectives and is associated with damage to a particular part of the brain. A different syndrome, called Broca's aphasia, results when there is a lesion in a different region of the brain, on the frontal lobe of the left cerebral hemisphere.
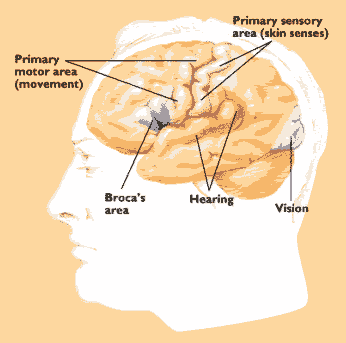
The most important symptom is an output problem: people with Broca's aphasia cannot speak fluently, tend to omit grammatical morphemes such as articles and verbal auxiliaries, and sometimes can hardly speak at all. Their comprehension, by comparison, seems relatively intact.
However, under careful study their ability to understand sentences turns out to be deficient in systematic ways. They always do well when the nouns and verbs in the sentence go together in a way that is much more plausible than any alternative:
It was the mice that the cat chased
The postman was bitten by the dog
However, if more than one semantic arrangement is equally plausible:
It was the baker that the butcher insulted
or if a syntactically wrong arrangement is more plausible than the syntactically correct one:
The dog was bitten by the policemen
then they do not do so well. Clearly Broca's aphasia has a negative impact on the processing of syntactic structure.
So how does the syntax of human languages actually work?
It is clear then that an important part of language is a more or less rigid structure of putting words together to form sentences, and we can understand pretty well why this should be. Syntax is a solution to the problem of clearly and consistently expressing relationships between entities and concepts in the linguistic utterance. In this section we will look at the main characteristics of the actual solutions that human languages employ.
A discrete combinatory system
One of the key characteristics of human language that is often overlooked because it is so obvious is that it is what we call a discrete combinatory system .
Discrete means that language is made up of not of undifferentiated masses of things, but of identifiable chunks that can be distinguished from one another. So sentences are made up a number of words, and a word is made up of a number of sounds, which we can isolate and label.
Combinatory means that these discrete chunks are put together to make larger units in consistent ways.
The genius of language is that it "makes infinite use of finite means", and the German scholar Wilhelm von Humboldt famously said. That is, there is a finite number of distinct sounds in any given language (perhaps about 40 in English), but these can be combined together in an infinite number of ways.
The fact that the number of discrete pieces is limited makes it possible to learn a language. You need to learn a short list of sounds, a much longer, but still principally finite list of words (or word stems), and a manageable number of rules to combine these together, and with them you can create a principally limitless number of sentences expressing all sorts of complicated ideas.
In this way, language is actually quite different from many other infinite systems. For example, given a few basic colors of paint, it is possible to mix and infinite number of intermediate shades by adding more or less of each to the mixture. This is nice for getting your living room to look just right, but it wouldn't very efficient for communication, because many of the intermediate shades would be very difficult to distinguish from one another. Things like paint mixing are called blending systems .
As Pinker notes, it's probably no accident that one of the other very important "codes" for transmitting information, the structure of DNA, is also based on a discrete combinatorial system. To this one can also add the basic building blocks of matter - chemistry. There too, a limited number of elementary particles - the quarks - combine systematically to form larger units - protons, electrons and neutrons - which in turn combine to form atoms and so forth.
Word order
So syntax involves the combination of what we can think of for now as indivisible atoms: the words of a language.
The most obvious aspect of this combination is word order, and indeed, this was the main concern of many early theories of syntax.
It is an inherent property of spoken language that an utterance is produced not at one instant, but over a certain amount of time, with the elements involved being ordered one after the other.
A basic observation about English word order is that it generally follows the pattern subject + verb + object (or "SVO").
| The dog | chased | the cat | |
| (subject) | (verb) | (object) |
If we change the word order, it changes the relation of the nouns to the verb.
| The cat | chased | the dog | |
| (subject) | (verb) | (object) |
This is because, as we noted earlier, English uses word order to mark the role of nouns in the sentence: normally the subject precedes the verb, and the object (if any) follows the verb.
But languages do not all use word order in the same way, and they do not all have the same possible orders.
In many languages, a morpheme (such as a suffix or preposition) is used to perform the same function. Latin is such an example: the case marker is a suffix that indicates whether the noun is functioning as a subject or object, or in some other role. ("Case" refers to the noun's relationship to the verb or some other element, such as a preposition.)
| Canis | fêlem | vîdit | |
| dog (subject) |
cat (object) |
saw (verb) |
We can change the relations to the verb while keeping the nouns in place, simply by modifying the case endings. As you can see, the suffix -em marks objects (the "accusative case"), while -is, for this class of nouns at least, is used for subjects (the "nominative case").
| Canem | fêlis | vîdit | |
| dog (object) |
cat (subject) |
saw (verb) |
Given the existence of case-marking suffixes, word order in Latin is not used the way it is in English: instead, it typically functions to provide information about what the speaker is focusing on, and whether the participants described are already known to the listener. This is the sort of thing that English does by more complicated phrasings.
The general rule is that putting anything but the subject first foregrounds it as a topic of the discourse:
Fêlem canis vîdit
"(Remember,) the dog saw a cat"
And putting anything after the verb emphasizes it very heavily:
Canis vîdit fêlem
"(No,) it was a cat that the dog saw (not a bird)"
Fêlem vîdit canis
"(No,) it was the dog that saw a cat (not the night watchman)"
It's important to remember that the relation of each noun to the verb is unchanged by the new word order: only the conversational emphasis differs.
Even a language with case markers can have a relatively fixed order. In Japanese, for example, the normal word order in a main clause is subject + indirect object + direct object + verb.
| Tarô ga | Hanako ni | sono hon o | yatta | |
| Tarô (subject) |
Hanako (indirect object) |
that book (direct object) |
gave (verb) | |
|
"Tarô gave that book to Hanako." | ||||
Thanks to the case markers (which here are postpositions: like prepositions, but they occur after the noun), the nouns can be reordered without changing their relation to the verb. Essentially, any one of the nouns can be moved to the front; this functions to mark that noun as the topic of the discourse.
| Hanako ni | Tarô ga | sono hon o | yatta | |
| Hanako (indirect object) |
Tarô (subject) |
that book (direct object) |
gave (verb) | |
| "To Hanako, Tarô gave that book." | ||||
| sono hon o | Tarô ga | Hanako ni | yatta | |
| that book (direct object) |
Tarô (subject) |
Hanako (indirect object) |
gave (verb) | |
| "As for that book, Tarô gave it to Hanako." | ||||
Since English has very minimal case marking -- just in pronouns such as we and us -- this kind of reordering would lead to confusion of meaning. Some reordering is possible, however, generally with clear intonation to make the unusual situation obvious.
Pat I like, but Chris I can't stand.
In this contrastive situation, the stress on the fronted nouns (objects of the verbs) helps the listener identify the special construction.
Sentences are not word strings
So the syntax puts words together in specific orders, but how does it do so?
The simplest way we can imagine would be for there to simply be a process that strings words together. Our generative grammar would then just be a series of instructions to determine the words of the sentence in sequence, one after another, each on the basis of what has come before.
One simple example of such a grammar given by Pinker is a grammar that generates social science jargon. The following is an excerpt, where the idea is to choose at random one word from each column:
| dialectical | participatory | interdependence |
| defunctionalized | degenerative | diffusion |
| positivistic | aggregating | periodicity |
| predicative | appropriative | synthesis |
| multilateral | simulated | sufficiency |
| quantitative | homogeneous | equivalence |
As Pinker notes, devices like this work just fine for simple tasks like the automated reading of recorded phone numbers, and they can even do a pretty good job of describing small portions of the grammar of a human language, but they are fundamentally unable to do the whole job.
The reason for this is that such devices have no memory. For example, in our social science jargon generator, our choice of words from the first column cannot affect our choice from the third column. In this instance this is exactly what we want, because the point of the joke is that such jargon is just a meaningless stringing together of buzzwords.
But real human language is quite different. There our choice of forms at a particular position in the sentence can very well depend on what forms occur in earlier positions.
Pinker gives some complicated examples of this, and I'll refer you to him for the full argumentation of this point. For our purposes, the following sentence is sufficient:
If Andrea hadn't eaten the fish, then she wouldn't have gotten sick.
By the time that we get to the word fish , there are at least three dependencies we need to keep track of in order to finish off the sentence properly:
- The word if requires a following clause where the consequence that will follow if the condition in the if-clause is fulfilled is laid out. This clause can only be introduced by then or nothing, not that, when, because or the like.
- Because Andrea is a woman's name (at least it usually is in the U.S.), the pronoun in the then clause that refers back must also be feminine, in this instance she .
- The past tense and irrealis mood of the verb had in the if clause restricts the tense and mood of the then clause to a subjunctive with would .
Constituent structure
The reason why word-string grammars don't work is because sentences have more to their structure than just a string of words. Like every level of linguistic structure, the syntax is hierarchically organized, each unit being composed of smaller subunits, which are in turn composed of smaller subunits and so forth.
A sentence is not composed directly of words, but of word groups, called phrases. There is a great deal of evidence for this.
For example, a simple (and inadequate) rule for creating a question from an English sentence is that you take the auxiliary verb and move it to the front of the sentence. (The notion "auxiliary verb" is discussed below.)
the dog is in the yard
is the dog __ in the yard?
But what if there's more than one such verb in the sentence? You can't just take the first one you find.
the dog that is in the yard is named Rex
*is the dog that __ in the yard is named Rex?
Rather, we need to identify the verb which is serving as the head of the main clause of the sentence:
the dog that is in the yard is named Rex
is the dog that is in the yard __ named Rex?
We can't understand this distinction without knowing how the pieces of the sentence fit together, i.e. their constituency.
In this case, we need to understand that the subject of the sentence might be complex, potentially containing one or more verbs of its own (in relative clauses that modify a noun).
[ my dog ] is named Rex
[ that dog ] is named Rex
[ the dog you just saw ] is named Rex
[ the dog that is in the yard ] is named Rex
[ the dog whose owner was arrested yesterday by the police for using him in a drug-running scheme ] is named Rex
All these sentences have the same structure except for the contents of the subject. What's important is that certain operations, like question formation, are only concerned with what is going on at the level of the sentence, not with what is inside the subject. Once it has been determined that, e.g., the dog that is in the yard is the subject, it is treated as a single unit, and the question rule looks past it to find the next verb. If sentences were just strings of words, this would be impossible.
There are several ways to determine whether a string of words is a constituent, i.e. a coherent grouping of words functioning as a syntactic unit.
All the subjects in the sentences about Rex can stand alone as answers to the question, Who is Rex?
Who's Rex? My dog!
That dog!
The dog you just saw!
The dog that's in the yard!
The dog whose owner was arrested yesterday by the police for using him in a drug-running scheme!
In contrast, many strings of words are not able to stand alone, and they are therefore not constituents.
*The dog you just!
*The dog that's in the!
*The dog whose owner!
A good test for constituency is whether a pro-form -- that is, a pronoun such as it or them, or the pro-verb do, do so, do it -- can replace the string of words.
[ the dog you just saw ]NP is named Rex
[ he ] is named Rex
I gave [ the book ]NP to Pat
I gave [ it ] to Pat
Did you [ give the book to Pat? ]VP
Yes, I [ did ]
Yes, I [ did it ] already
Yes, I [ did so ] yesterday
The pro-form replaces an entire constituent.
Another test for a constituent is whether it can move as a unit. An example is the construction called a cleft sentence.
It's [ my dog ] that's named Rex
It's [ the dog that is in the yard ] that's named Rex
Examples for the sentence I gave the book to Pat; the underline indicates where the string of words has been moved from.
It's [ the book ] that I gave __ to Pat
It's [ to Pat ] that I gave the book __
It's [ Pat ] that I gave the book to __
*It's [ the book to Pat ] that I gave __
*It's [ gave the book ] that I __ to Pat
*It's [ gave to Pat ] that I __ the book
It's [ gave the book to Pat ] that I did
In the last example, we see the use of a pro-form to substitute for the entire verb phrase, which of course is another test. (In a context like this, there has to be some kind of verb phrase remaining after the constituent is moved, so a form of did is used to fill the void.)
Phrase-structure rules
So sentences are not just strings of words, but are composed of a series of constituents which are themselves made up of words. It turns out that these constituents generally correspond to phrases built around specific types of word, what we call lexical categories or, more traditionally, parts of speech.
The phrases that are built around different lexical categories are different in a lot of ways, but in many others they are very similar. We will look at the basics here.
For example, a noun is a single word (or compound).
N | dog
A noun phrase is a constituent of a sentence that is built around a noun (which is what we call the head of the phrase), with other elements such as determiners and adjectives, or a relative clause or other modifier.
NP
NP / | \
/ \ / | \
Det N Det Adj N
| | | | |
the dog a big dog
We use tree diagrams like these to encode constituency, to represent the interrelations of the individual words. They are created -- in the speaker's mind, or in a computer model of the speaker's knowledge -- by means of general principles called phrase structure rules. These determine what kinds of sentence structures are possible in a language.
The phrase structure rules that permit these configurations are as follows:
NP ---> Det N
NP ---> Det Adj N
We can imagine many other variations on these noun phrases as well, of course.
the dog
the big dog
a big brown dog
big angry brown dogs
A way to unify these different types of noun phrase is to write a more complex phrase structure rule.
NP ---> Det Adj* N
The asterisk means that an NP consists of a determiner, any number of adjectives, and a noun.
To account for phrases like the following, we refer to an Adjective Phrase rather than just an adjective:
[ a ]Det [ very big ]AdjP [ slightly brownish ]AdjP [ dog ]N
So, correcting the rule again:
NP ---> Det AdjP* N
Now, sometimes a noun phrase will be modified by another kind of constituent, a prepositional phrase, as in the dog in the yard :
NP
/ \
/ \
NP PP
/ \ / \
Det N P NP
/ | | | \
the dog in Det N
| \
the yard The phrase structure rule for this structure is rather simple:
NP ---> NP PP
Simple as it is, such a rule demonstrates one of the key properties of language, which is that a single category can appear on both sides of the arrow of a phrase structure rule. This is called recursion, and is the main way that a finite grammar can derive an infinite number of structures.
We also need to "spell out" the prepositional phrase:
PP ---> P NP
Because we already have a rule for NP, we can apply the rules in succession.
NP ---> NP PP
NP PP ---> NP P NP
NP P NP ---> Det AdjP* N P Det AdjP* N
Together these rules will produce the structures for complex NPs such as:
[ dogs ] [ on tables ]
[ the young brown dog ] [ under the big green tree ]
We can also apply the rules successively to produce more than one PP.
NP ---> NP PP
NP PP ---> NP PP PP
NP PP PP ---> NP P NP PP
NP P NP PP ---> NP P NP P NP
This yields the following tree. Follow the top node (NP) down to its dependents (NP and PP) and you see the effect of the first rule; keep going down to see the effect of the remaining rules. The tree structure is built by the rules.
NP
/ \
NP \
/ \ \
/ PP PP
/ /\ /\
NP P NP P NPWe would keep going (applying the NP rule discussed above) to get to the individual words that make up the NPs at the bottom of this tree. For example:
[ the dog ] [ under the tree ] [ with brown fur ]
Here with brown fur modifies the dog just like under the tree does.
But suppose we apply the rules in a different way:
NP ---> NP PP
NP PP ---> NP P NP
NP P NP ---> NP P NP PP
NP P NP PP ---> NP P NP P NP
Now we get a different tree:
NP
/ \
/ PP
/ / \
/ / NP
/ / / \
/ / / PP
/ / / /\
NP P NP P NPA phrase matching this structure is the following:
[ the dog ] [ under [ the tree with dead leaves ] ]
Notice that here, with dead leaves modifies the tree -- the NP lower in the structure, to which it is adjoined -- and the PP under the tree with dead leaves modifies the dog, because it's adjoined as a single unit.
These two sentences have the same linear order of elements (with the last adjective and noun changed), but different constituency. The possibility of two constituencies for the same string of words is what leads to structural ambiguities.
A famous example of structural ambiguity is a joke told by Groucho Marx in Animal Crackers.
|
How he got into my pajamas I dunno. |
 |
|
Click for more Marx Brothers Sound Bites. |
The ambiguity here centers on the prepositional phrase in my pajamas: does it modify the noun elephant, or the entire verb phrase? The simple linear order is consistent with either:
| I | shot | an elephant | in my pajamas | |
| subject | verb | noun phrase | prep phrase |
The more reasonable meaning is "I shot an elephant while (I was) in my pajamas." This is parallel to a sentence like I [bought a book [with my credit card]].
| I | shot | an elephant | in my pajamas | |
| subject | verb | noun phrase | prep phrase | |
| verb phrase | ||||
Or, as a tree:
S
/ \
NP VP
/ / \
I VP PP
/ \ \
V NP in my pajamas
| |
shot an elephantAlso possible, though, is "I shot an elephant that was in my pajamas." This is parallel to a sentence like I bought [a book [with a red cover]].
| I | shot | an elephant | in my pajamas | |
| subject | verb | det+ noun | prep phrase | |
| noun phrase | ||||
| verb phrase | ||||
And as a tree, where we see that the phrase in my pajamas is more intimately connected to an elephant than it was in the preceding structure. This closer structural connection is what encodes the idea that it modifies elephant rather than the act of shooting.
S
/ \
NP VP
/ / \
I V NP
/ / \
shot NP PP
/ \
an elephant in my pajamasSo the ambiguity results from which order we decide to apply the phrase structure rules in. Again, a grammar that consisted of simple word strings would be incapable of capturing this.
Now, the phrases discussed here illustrate the importance of recursion, hierarchical structure, and the generality of the phrase structure rules -- the same spelling out of NP occurs whether the NP is part of a PP or not.
In principle, any combination of correctly formulated phrase structure rules will yield a possible sentence structure in the language.
A verb phrase is another type of constituent which includes the verb and its complements, such as a direct object, indirect object, and even a sentence. (A complement is what Pinker calls a "role-player" as distinct from a modifier.)
they [ saw me ]
she [ gave the book to me ]
you [ said that you would arrive on time ]
There's a fundamental division in a sentence between the subject (an NP) and the verb phrase (VP). In more philosophical contexts, these are often referred to as subject and predicate (the thing discussed, and what's said about it).
Because of this, the first rule in our phrase structure grammar will look something like this:
S ---> NP VP
S / \ NP VP
That is, a sentence consists of a subject NP, and a verb phrase.
The internal structure of the verb phrase depends on the nature of the verb.
intransitive: verb does not have an object
laugh, frown, die, wait, fall
VP ---> V
S / \ NP VP | Vtransitive: verb has an object (= an NP complement)
see, want, like, find, make
VP ---> V NP
S / \ NP VP | \ V NPditransitive: verb has two objects
give, tell, buy, sell, send
VP ---> V NP NP
S / \ NP VP / | \ V NP NP
Another spell-out is VP ---> V NP PP, to yield the synonymous I gave the book to you alongside I gave you the book.
Often the same verb can belong to more than one class.
I already [ ate ]
I already [ ate the apple ]She [ told ] as in, "I'm gonna tell!"
She [ told a story ]
She [ told me a story ]
It's also possible for a verb to take complements that aren't NPs, at least not in any simple sense.
We [ told him the truth ]
We [ told him that we were leaving ]They [ want the book ]
They [ want to leave ]
They [ want you to leave ]
There are a number of other complications and details with phrase structure that you can learn about if you take a course in syntax, like Ling 150, Introduction to Syntax.
Transformations
Another interesting property of human language syntax is the phenomenon sometimes referred to as displacement, which refers to situations where an element (a word or constituent) appears in some position other than where we would expect it. We have already seen some examples of this, like topicalization sentences of the following type:
Him I don't like.
Normally, we would expect him to show up after the verb, because it is the direct object, and English direct objects generally follow the verb.
Another example is the passive construction, where the object of the verb becomes subject, and the subject either disappears or shows up in prepositional phrase with by:
Bobby stole the Datsun.
The Datsun was stolen (by Bobby).
We can say that the second sentence is the passive of the first. Here again, we have a constituent, in this case the Datsun showing up in a different position than we might expect. It is the subject here, occurring before the verb, but as far as the meaning is concerned, it is still the object, the thing that is being acted upon, not the actor.
There are many ways we could try to account for this state of affairs, but Chomsky has argued that the best way to do it is not to just add extra phrase structure rules. Instead, he introduced the notion of a transformation, (which is an adaptation of a somewhat different idea proposed by his teacher, Zellig Harris).
The idea is basically this. We use the phrase-structure rules to derive a basic sentence. Thus, given a simplified version of the rules above:
We can have the following derivation:S ---> NP VP
NP ---> (DET) NP
VP ---> V NP
S ---> NP VP
NP VP ---> NP V NP
NP V NP ---> NP V DET NP
NP V DET NP ---> Bobby stole the Datsun
Following the work of the phrase structure rules, another portion of the syntax goes to work, which can move elements around. In this instance, we apply the passive transformation, which takes a sentence, demotes the subject, and promotes the object to subject position, yielding the passive sentence The Datsun was stolen by Bobby.
Now, in order for a theory of this type to be interesting, transformations must be highly constrained. It should not be possible to move anything one likes, because then we would predict all sorts of sentences to be grammatical that in fact are not.
Syntactic theory for the past several decades has been working on figuring exactly what sort of transformations should be possible, as well as determining which phenomena should be explained by means of transformation and which are better explained through use of phrase structure rules.
For example, in recent years it has come to be accepted that all transformations can be formulated in terms of single constituents moving around within the tree, not in terms of, say, phrases swapping places or being added randomly.
Another restriction that has been proposed is that constituents only move if they have to in order to satisfy some grammatical principle. One such principle, at least in English, seems to be that all sentences must have a subject. This is demonstrated by the following examples:
a) It seems that all my friends are sick.
b) *Seems that all my friends are sick.
c) My friends seem to all __ be sick.
Setence a) has two clauses (mini-sentences), the main clause It seems , and the subordinate clause containing that and everything after it. The subject of the subordinate clause is my friends, they are the ones who are sick.
The subject of the main clause is the word it , which actually has no meaning. It does not refer to anything in the world, not even an abstract idea. Apparently, it just shows up here because the sentence needs a subject. If we leave out it , as in sentence b), the sentence is ungrammatical (we mark ungrammatical sentences with an asterisk).
But there is a different way to say essentially the same thing here. We can put the subject of the subordinate clause, my friends, in the subject position of the main clause. This actually constitutes very good evidence that it in sentence a) has no meaning, because we've left it off here without really affecting the meaning of the sentence.
Now, can my friends have started out as the subject of the main clause? Probably not, because as far as the meaning goes, it's still the subject of the subordinate clause. They are still the ones who are sick. So we have another situation where an element shows up in one place when we expect it to be in another. This is therefore standardly analyzed as another instance of a movement transformation.
Note that here we actually have some extra evidence that my friends started out in the subordinate clause and moved up to the main clause: the position of the word all. This word modifies my friends in sentence c) just as it does in sentence a), yet it is separated from it. It thus looks like this sentence started out looking something like sentence b), but then my friends moved up to the main clause, leaving its modifier behind.
Now we have a very attractive possibility for explaining why this movement should have taken place. If it did not, we would get b), which is ungramatical because the main clause has no subject. The movement is thus forced by the lack of a main clause subject.
In sentence a), on the other hand, movement is unnecessary (and impossible), because the subject requirement in the main clause has been satisfied by the meaningless element it.
The full analysis of sentences like this involves a number of further complications, and in all fairness I should note that recent versions of Chomsky's syntactic theory look rather different from what we've seen here in the details, but the basic ideas are still the same.
Non-Chomskyan approaches to syntax
While Chomsky is the most influential syntactician and has been for 45 years or so, and while more theoretical linguists work more or less within his theories than anyone else's, I do not wish to give the impression that his ideas are universally accepted, or that alternatives do not exist.
Indeed, he is criticized as much as he is praised, and there are a number of non-Chomskyan and even anti-Chomskyan movements out there. It is not possible to do them justice in an Intro to linguistics class, or even to mention all of the important theories, in part because to a certain extent the issues on which the various theories disagree are rather technical.
If you go on to take courses such as Ling 106 and Ling 150, you will get the background needed to understand these efforts in detail, as well as to follow the interesting twists and turns of the Chomskian linguistic enterprise over the past 40 years. For now, if you're interested, you can get a sense of what a few other contemporary approaches to syntax are like, by browsing their web sites: